Vor etwa einem Jahr habe ich meinen Mietserver bei Netcup gekündigt uns hoste nun alles selbst. Auf einem Thin-Client. Genauer auf einem HP T630. So ganz konkret zum handeln gebracht hat mich das Video Gebrauchte Thin-Clients im Test
auf dem Heise-Youtube-Kanal Ct'3003. Inzwischen hat der Home-Server auch schon einige Upgrades erfahren. Um die Hardware soll es in diesem Shaare gehen.
Ein wichtiger Aspekt war für mich, dass das Gerät leise ist. Und das ist der T630 auch, weil er nämlich keinen Lüfter besitzt. Der zweite Punkt ist der Stromverbrauch. Ich habe im Betrieb eine Leistungsaufnahme von 11-13 Watt gemessen. Das ist leider mehr als ein vergleichbareres Gerät mit einem Intel J4105 Chipsatz, der etwa die Hälfte verbraucht, dafür aber in der Anschaffung teurer ist. Wenn man das durchrechnet kostet der T630, bei einem Strompreis von 33 pro kWh, etwa 30 Euro im Jahr. Das ist auf jeden Fall schon mal weniger, als ein angemieteter Server. Und weil der Anschaffungspreis des T630 am günstigsten war, ist es eben dieser geworden.
Hardware
Die Details kann man sich aus der QuickSpecs (PDF) herauslesen. Entscheidend finde ich folgende Infos.
Specs
- CPU AMD GX420-GI
- GPU AMD Radeon R7E
- RAM 2x SO-DIMM Slots, die man mit bis zu 2x16GB bestücken kann. Ich habe 1x16GB, was bisher mehr als genug ist.
- 2x m.2 SATA Slots
- 1x m.2 für einen Wifi/Bluetooth-Adapter
- 3x USB-A 3.0. Zwei an der Front und einer im Gehäuse, was kreative Einsatzmöglichkeiten bietet. Allerdings kann man vom internen USB-Port nicht booten.
- 4x USB-A 2.0. Zwei an der Front, zwei an der Rückseite.
- 2x DisplayPort 1.2. Leider kein HDMI dafür aber noch einen VGA-Port.
- 1x Gigabit RJ45 / LAN
RAM-Upgrade
Es genügen günstige DDR4 SODIMM / 1866Mhz RAM-Module mit 260 Pins. Es Funktionieren aber auch Riegel mit höherem Takt wie 2133Mhz, 2400Mhz, 2666Mhz, 2933Mhz oder 3200Mhz. Diese laufen dann aber nur mit 1866Mhz.
- Crucial-CT2K16G4SFRA32A (Amazon)
ECC-RAM
Der Chipsatz des T630 ist für den Betrieb von ECC-RAM geeignet. Das kann man im Bios leider nicht aktivieren, aber dafür direkt unter Linux mit
modprobe -v amd64_edac ecc_enable_override=1und zum testensudo dmesg | grep -i edac.
Wenn alles wunschgemäß aussieht, mit folgendem Befehl dauerhaft persistieren.sudo echo "options amd64_edac ecc_enable_override=1" >> /etc/modprobe.d/amd64_edac.conf
m.2 SATA SSDs nachrüsten
Die beiden m.2 Schnittstellen funktionieren nur mit SATA-SSDs. Man kann also keine NVME-SSDs verwenden. Ich habe eine Transcend M.2 SSD TS2TMTS830S eingebaut. Entscheidend für mich waren die langlebige MLC-3D-NAND-Flash-Bausteine.
Zweiten Netzwerk-Port nachrüsten
Zwar ist keine zweite Netzwerkschnittstelle vorgesehen, aber kann man den m.2 2230 Slot (Wifi-BT-Karte) dafür nutzen. Ein- oder mehrere USB3-Netzwerkadapter funktionieren aber auch. Tatsächlich ging das bei mir sogar überraschend stabil.
- M.2 a e Key 2,5g Ethernet LAN-Karte rtl8125b (Aliexpress)
- Einbauanleitung (Youtube)
- Einbauanleitung - How to install an extra NIC
Netzteil
Der T630 hat einen HP-Typischen, 7,4mm Netzstecker mit Smartpin. Das ist nervig, wenn man ein neues Netzteil beschaffen muss. Oft werden die Geräte auch besonders günstig ohne Netzteil angeboten. Besonders einfach geht es mit einem USB-C Adapter, der es erlaubt, jedes USB-C Netzteil, das 19-20V bei wenigstens 65 Watt liefert, anzuschließen. Auf diese Idee bin ich leider etwas zu spät gekommen.
Mods aus dem 3D-Drucker
- Schale für die Wandmontage (cults3d)
- Geräte-Ständer (cults3d) oder Geräte-Ständer (thingiverse)
- Adapter fuer zweite m.2 2280-Full-Size SSD (thingiverse)
Wärmeleitpaste erneuern
Links

Innenleben des HP T630

Wie unschwer zu erkennen ist, läuft dieser Blog (wenn man ihn so nennen mag) auf der Software Shaarli. Hauptsächlich für Bookmarks gedacht, ist das trotzdem für mich der fast perfekte Micro-Blog. Das liegt daran, dass er unkompliziert, schnell und arm an Features ist. Das hilft mir beim Fokussieren auf das Wesentliche: den Inhalt.
Was mir jedoch fehlte, war die Möglichkeit, auch mal ein Bild oder einen Screenshot hochzuladen. Zum Glück bietet Shaarli die Möglichkeit, Funktionalitäten per Plugin nachzureichen. Also habe ich einfach einen Upload-Button beim Erstellen eines Beitrags hinzugefügt und beim Speichern das Bild passend abgelegt und einen Markdown-Link eingefügt. PHP und das Plugin-System von Shaarli sind nicht schwierig. Da ich jedoch nur gelegentlich etwas mit PHP mache und das Plugin-System gar nicht kenne, habe ich mir von Chat-GPT helfen lassen. Wie zu erwarten nimmt einem die KI natürlich nicht alles ab und manches ist Quatsch, aber sie hat sich auch vielfach hilfreich verhalten und mir so geholfen, an einem Nachmittag eine brauchbare Lösung zusammenzubekommen. Das fertige Plugin habe ich bei Github abgelegt.
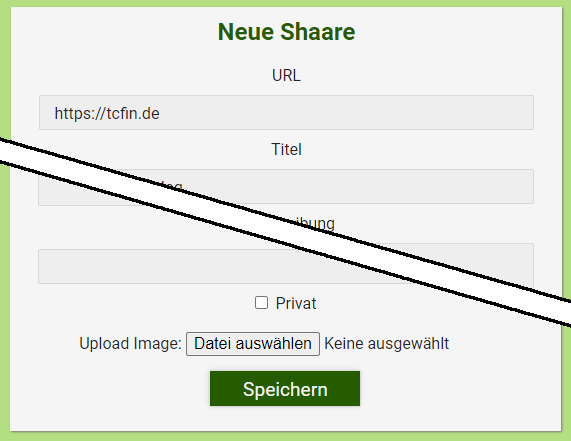
Neuen Beitrag in Shaarli erstellen mit Button zum Bild hochladen
Links
Shaarli The personal, minimalist, super fast, database-free, bookmarking service.
Neulich gab es als Promo 50 Gigabyte kostenlosen Onlinespeicher bei Bitrix24.de. Eine sehr gute Gelegenheit die wichtigsten Daten aus dem Home-Server ins Internet zu kippen. Leider funktioniert das Mounten per Webdav wegen veralteter Cipher, die von Bitrix24 Verwendung finden und bei davfs2 schon entfernt wurden, nicht. Ein einfacher Upload mit curl geht aber auch so.
tar -czvf - -C path/to/important/files . | openssl aes-256-cbc -salt -k 'enc_passwd123!' -pbkdf2 | curl -T - -u [email protected]:bitrix_password https://b24-w0e67a.bitrix24.de/company/personal/user/1/disk/path/backup.tar.encWir packen also alles aus dem lokalen Verzeichnis path/to/important/files zusammen, verschlüsseln es mir einem ordentlichen Passwort und laden die Datei bei Bitrix24.de hoch.
Die Backup-Datei kann man testweise wieder herunterladen und mit der folgenden Zeile entschlüsseln und z.B. nach /tmp/restore entpacken.
cat backup.tar.enc | openssl aes-256-cbc -d -salt -k 'enc_passwd123!' -pbkdf2 | tar -xzvf - -C /tmp/restoreWenn man das ganze automatisieren will, will man vielleicht die alte, hochgeladene Datei vor dem nächsten Upload löschen.
curl -X DELETE -u [email protected]:bitrix_password https://b24-w0e67a.bitrix24.de/company/personal/user/1/disk/path/backup.tar.encDie Datei wandert bei Bitrix24.de leider nur in den Papierkorb und nimmt auch weiterhin Platz ein, bis sie entweder automatisch nach 30 Tagen gelöscht oder der Papierkorb von Hand geleert wird.
Um das ganze zu automatisieren und außerdem einen Mechanismus zum Chunken zu haben, habe ich aus dem ganzen ein Python-Script zusammengebastelt, das regelmäßig per Cron ausgeführt wird. Wichtig war mir hierbei, daß keine Daten auf die SSD zwischengespeichert werden, um diese zu schonen und außerdem den RAM-Verbrauch nicht explodieren zu lassen. Es wird also alles per Pipe durchgereicht, so dass die Chunksize maßgeblich für den RAM-Verbrauch ist.
import os
import subprocess
import sys
def create_backup(directory):
# Archiv erstellen und verschlüsseln
tar_process = subprocess.Popen(["tar", "-zcf", "-", directory], stdout=subprocess.PIPE)
encrypt_process = subprocess.Popen(["openssl", "aes-256-cbc", "-salt", "-k", "enc_passwd123!", "-pbkdf2"], stdin=tar_process.stdout, stdout=subprocess.PIPE)
# Chunk-Größe festlegen 100MB (in bytes)
chunk_size = 100 * 1024 * 1024
# Verzeichnisname des Backup-Verzeichnisses extrahieren
backup_directory, backup_dirname = os.path.split(os.path.normpath(directory))
print( f"backup_dirname={backup_dirname}" )
# Chunks erstellen und hochladen
chunk_number = 1
while True:
chunk = encrypt_process.stdout.read(chunk_size)
if not chunk:
break
# Chunk hochladen
upload_chunk(chunk, chunk_number, backup_dirname)
chunk_number += 1
# Aufräumen
encrypt_process.stdout.close()
encrypt_process.wait()
def upload_chunk(chunk, chunk_number, backup_dirname):
filename = f"backup_{backup_dirname}_{str(chunk_number).zfill(3)}"
delete_command = f"curl -X DELETE -u [email protected]:passwd123! 'https://b24-w0e67a.bitrix24.de/company/personal/user/1/disk/path/{filename}'"
subprocess.run(delete_command, shell=True)
upload_command = f"curl -i -X PUT -u [email protected]:passwd123! --data-binary @- 'https://b24-w0e67a.bitrix24.de/company/personal/user/1/disk/path/{filename}'"
subprocess.run(upload_command, input=chunk, shell=True)
# Kommandozeilenparameter überprüfen
if len(sys.argv) < 2:
print("Verzeichnis als Parameter angeben.")
sys.exit(1)
# Verzeichnis aus Kommandozeilenparameter extrahieren
directory = sys.argv[1]
# Beispielaufruf des Skripts
create_backup(directory)Aufgerufen werden kann das Script einfach mit python3 <scriptname> path/to/important/files.
Eine Subdomain zum Homelab / Homeserver einrichten
Wenn man seine Domain bei Cloudflare verwalten lässt, bekommt man im kostenlosen Plan die Möglichkeit Dynamic DNS zu nutzen gleich mit, sodass man seine Domain oder Subdomain immer auf den Homeserver zeigen lassen kann. In meinem Fall will ich eigentlich nur einen VPN-Tunnel in mein Homelab aufbauen und benötige dafür eine dauerhafte Adresse.
Subdomain anlegen
Wenn man nur eine Subdomain anstelle der Hauptdomain für das Homelab verwenden will, legt man diese am besten erst mal im Cloudflare-Dashboard an. Dafür klickt man auf "Add record" und wählt für IPv4 den Typ A oder für IPv6 den Typ AAAA aus. Anschließend unter Name den Namen der Subdomain eintragen und auf Speichern klicken.

Lässt man den Schalter "Proxy" eingeschaltet, bleibt die eigentliche IP trotz Weiterleitung des Traffic an den Homeserver geheim. Mehr dazu siehe link. Will man allerdings einen VPN-Tunnel aufbauen, muss man leider auf den Proxy verzichten.
API-Key erzeugen
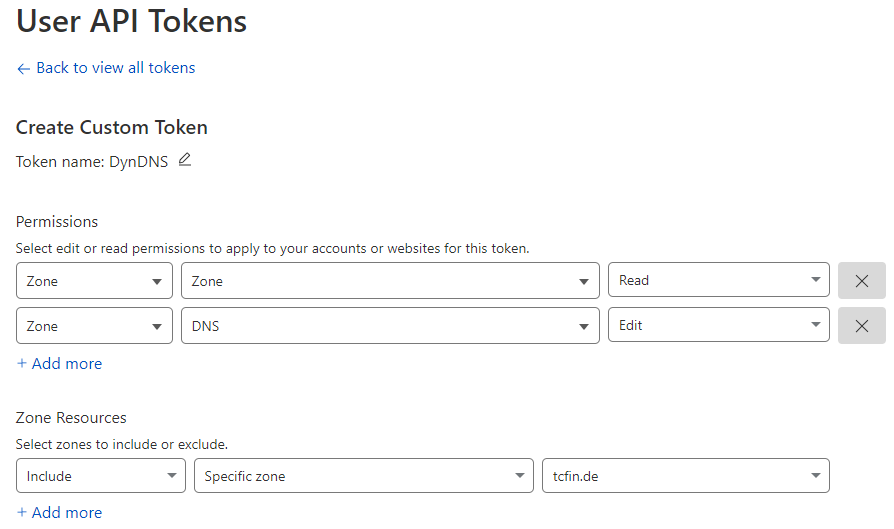
Als nächstes benötigen wir einen API-Key, mit dem sich der PfSense-DynDns-Client bei Cloudflare anmelden kann. Sinnvollerweise sollte der Key nur die notwendigen Rechte haben, um DNS-Einträge einer bestimmten Domain zu ändern. Dafür klickt man unter User API Tokens auf "Create token" und wählt dort "Create Custom Token" aus.
Anschließend erstellt man unter "Permissions" zwei neue Zonen-Einträge. Einmal mit "Zone" und "Read" und einmal "DNS" und "Edit". Unter "Zone Resources" fügt man noch einen Eintrag mit "Specific zone" hinzu und wählt die zu verwendende Domain aus.
Damit kann der Client mit dem API-Key, der nach dem Speichern angezeigt wird, ausschließlich Änderungen an der ausgewählte Domain vornehmen.
PfSense Dynamic DNS
Um die frisch angelegte Subdomain automatisch zu aktualisieren, ruft man das PfSense-Dashboard auf und klickt im Menü "Services" auf "Dynamic DNS". Hier kann man nun einen Eintrag hinzufügen. Unter "Service Type" wählt man nun "Cloudflare" aus, wählt das passende WAN-Interface aus und trägt den API-Key als Passwort ein. Unter Hostname muss der Subdomain-Name und unter Domain die Hauptdomain eingetragen werden.
Hat man den Cloudflare-Proxy eingeschaltet, sollte man unbedingt auch die Checkbox "Cloudflare Proxy" aktivieren, weil sonst der Proxy nach dem ersten IP-Update deaktiviert ist und die eigene IP sichtbar wird.
Am Ende "Save and Force Update" anklicken und man hat einen neuen Eintrag, der auch gleich ein grünes Häkchen bekommt, wenn man alles richtig gemacht hat.
Glasfaser der Telekom ans Fliegen kriegen
Kürzlich war es so weit. Ich habe den heiß ersehnten Glasfaseranschluss bekommen. Und das auch noch zum Black-Friday-Tarif bei 1&1. Das ist inzwischen schon fast ein Jahr her. Den selbst gebauten Ubuntu-Router damit ans Fliegen zu bekommen, war etwas anspruchsvoller, als das Setup mit dem Kabel-Modem von Vodafone zuvor, das einfach per DHCP zu konfigurieren war.
Es brauchte ein PPPoE-Interface, wie man es von den DSL-Anschlüssen seit jeher kennt. Bei den Glasfaser-Anschlüssen hat sich die Telekom allerdings etwas Neues einfallen lassen. Man kann nicht länger einfach PPPoE auf das Netzwerkinterface konfigurieren, an dem das DSL-Modem hängt. Man muss zusätzlich ein VLAN mit der ID 7 einrichten. Ich habe dafür die Networkmanager-CLI benutzt.
Mein WAN-Netzwerkinterface heißt enp1s0. Die PPPoE-Credentials muss man natürlich passend ersetzen. Falls man noch eine Konfiguration für das Netzwerkinterface in der Netplan-Konfiguration unter /etc/netplan/01-network-manager-all.yaml hat, sollte man diese ggf. vorher deaktivieren.
nmcli connection add type vlan vlan.parent enp1s0 vlan.id 7 ipv4.method disabled ipv6.method ignore
nmcli connection add type pppoe username 1und1/[email protected] password XXXXXXXX ifname ppp1 pppoe.parent enp1s0.7Die neuen Interfaces für das VLAN und das PPPoE lassen sich bei Bedarf wie folgt wieder entfernen.
nmcli connection delete pppoe-ppp1
nmcli connection delete vlanLinks:
VLAN How to do pppoE with ISP "Deutsche Telekom" using ifname ppp1 pppoe.parent enp3s0.7
Rhasspy ist ein tolles Projekt, um einen eigenen Sprachassistenten aufzusetzen. In meinem Fall soll Rhasspy mit dem Low-Code-Service Node-Red kommunizieren, um die eingesprochene Frage an ChatGPT weiterzuleiten. Standardmäßig benutzt Rhasspy dafür Kaldi. Damit Rhasspy mit Kaldi das gesamte Gesprochene transkribiert und nicht nur die konfigurierten Sätze, muss man Kaldi mit der Option "Open transcription mode" konfigurieren. Nach dem Herunterladen des größeren Sprachmodells funktioniert das auch so halbwegs. Leider ist die Transkription oft zu ungenau, als dass sie für die Weitergabe an ChatGPT taugen würde. Deshalb wollte ich es mit Whisper von OpenAI versuchen.
Da ich ohnehin einen API-Key bei OpenAI angelegt habe, um von Node-Red meine Anfrage an ChatGPT zu senden, liegt die Verwendung von Whisper sehr nahe. Whisper ist eine Speech-To-Text (STT)-API, mit der sich Sprache in Text umwandeln lässt. Das funktioniert wirklich ganz ausgezeichnet und die Worterkennung ist viel besser als lokal mit Kaldi.
Für die Einbindung kann man bei Rhasspy-Speech to Text einfach "Local Command" auswählen. Das verlinkte Skript speichert das Eingesprochene in eine WAV-Datei und schickt diese an OpenAI-Whisper. Das Skript sieht dann so aus.
# WAV data is avaiable via STDIN
wav_file="$(mktemp).wav"
trap "rm -f $wav_file" EXIT
cat | sox -t wav - -r 16000 -e signed-integer -b 16 -c 1 -t wav - > "$wav_file"
# Api-Key for Authorization
OPENAI_API_KEY="<api-key>"
# Send the wav recording to openai whisper
curl https://api.openai.com/v1/audio/transcriptions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: multipart/form-data" \
-F file="@$wav_file" \
-F model="whisper-1" | jq -r '.text' | sed 's/[[:punct:]]//g'
# delete the wav recording file
rm "$wav_file"Der so erzeugte Text kann nun an Node-Red gesendet werden, welches sich dann um eine passende Antwort von ChatGPT kümmert. Das Fragen beantworten funktioniert sehr gut. Ich würde sagen, sogar besser als bei Alexa, die einem doch oft unzutreffendes erzählt. Weil aber Whisper und ChatGPT herhalten müssen, kann von einer offenen Open Source-Lösung nicht mehr die Rede sein. Aber da entwickelt sich gerade wirklich viel. Ich freue mich jedenfalls darauf auch diese Cloud-Dienste durch etwas zumindest in teilen lokal gehostetes zu ersetzen.
Links
Mein Homeserver soll ein Backup auf eine externe Festplatte erhalten. Eine Festplatte liegt noch herum und dazu eine schaltbare Steckdose. Wird die Steckdose eingeschaltet und die Festplatte gemountet, soll das Backup-Script automatisch gestartet werden. Nach Backup-Fertigstellung muss die Festplatte wieder abgemeldet und ausgeschaltet werden. Das geht mit einer manuell schaltbaren Steckdose oder vollautomatisch, wenn man eine Hue-Bridge mit passender Steckdose hat.
Das Festplattenbackup
Als erstes muss die Festplatte nach dem Anstecken gemountet werden. Für den Ubuntu-Desktop funktioniert so etwas Out-of-the-Box aber ohne Desktop und angemeldeten Benutzer muss man etwas tun. Damit man sich nicht lange mit Udev-Rules herumärgern muss, gibt es das sehr komfortable Tool udev-media-automount das jedes Laufwerk, das keinen Eintrag in der fstab vorzuweisen hat, kurzerhand nach /media mountet.
Damit nach dem Mounten ein Backup-Script ausgeführt wird, bauen wir uns ein Script, dass auf das Mounten der Backup-Festplatte wartet.
vim /home/user/bin/my_backup_watchdog.shund der neue Backup-Watchdog wie folgt angelegt.
#!/bin/bash -v
# Pfad zum Mount-Punkt
MOUNT_POINT="/media/Your_Media_Label"
# Pfad zum Backup-Skript
BACKUP_SCRIPT="/home/user/bin/my_backup.sh"
# Endlosschleife, um den Mount-Zustand zu überwachen
while true; do
if mountpoint -q "$MOUNT_POINT"; then
echo "Das Gerät ist gemountet, rufe das Backup-Skript $BACKUP_SCRIPT auf"
$BACKUP_SCRIPT
# Warte, bis das Gerät nicht mehr gemountet ist
until ! mountpoint -q "$MOUNT_POINT"; do
sleep 1
done
echo "Das Gerät ist nicht länger gemountet."
rmdir $MOUNT_POINT
fi
sleep 5
doneDas neue Backup-Watchdog-Script bei einschalten der Festplatte zu starten, lässt sich elegant mit einem systemd-Service bewerkstelligen. Zu erst also einen passenden Service anlegen.
vim /etc/systemd/system/my_backup_watchdog.serviceund den neuen Backup-Service wie folgt konfigurieren.
[Unit]
Description=My device trigger Script
After=network.target
[Service]
User=root
WorkingDirectory=/home/guru/bin
ExecStart=/home/user/bin/my_backup_watchdog.sh
Type=idle
[Install]
WantedBy=multi-user.targetZuletzt noch den systemd-Service aktivieren.
sudo systemctl enable my_backup_watchdog.serviceund starten
sudo systemctl start my_backup_watchdog.serviceUnd nach dem ersten Aus- und wieder Einschalten der Backup-Festplatte prüfen, ob das Backup-Script gelaufen ist.
sudo journalctl -xef -u my_backup_watchdog.serviceDas Backup-Script my_backup.sh enthält in meinem Fall nur ein rsync-Aufruf, der alle Docker-Volumes sichert, die auf _data, _config oder _backup enden.
#!/bin/bash -v
rsync -avL --delete --include='*_data/***' --include='*_config/***' --include='*_backup/***' --exclude='*' "$SOURCE_DIR" "$DESTINATION_DIR"
umount "$DESTINATION_DIR"Automatisches Einschalten der Backup-Festplatte
Über die Hue-Smartphone-App lässt lassen sich Timer einstellen. Einfach unter "Automatisierung" den Timer für die Steckdose stellen. Jedes Mal, wenn die Steckdose per Timer eingeschaltet wird, wird die Festplatte eingehängt und das Backup gestartet.
Automatisches Abschalten der Backup-Festplatte
Das händische Ausschalten der Backup-Festplatte nach Beendigung des Backups ist in diesem Setup noch der dumme Teil. Wer eine Hue-Bridge hat, kann das automatisch erledigen, in dem man der Hue-Bridge das Signal zum Ausschalten der Steckdose übermittelt.
Als erstes muss man einen authorisierten Username auf der Hue-Bridge generieren. Dafür den Schalter der Hue-Bridge drücken und folgendes Curl-Statement absetzen.
curl -X POST https://<bridge ip address>/api -H "Content-Type: application/json" -d '{"devicetype":"my_hue_script#homeserver peter"}' --insecureMan erhält nun den Username zurück, mit dem man im weiteren Verlauf alle Geräte abrufen und auch schalten kann. Das folgende Curl-Statement fragt die schaltbaren Geräte ab. Das sind neben den Leuchten eben auch Steckdosen.
curl -X GET https://<bridge ip address>/api/<username>/lights --insecureDie Rückgabe enthält alle Geräte. Das oberste Element ist jeweils eine Ziffer, mit der sich das Gerät ansteuern lässt. Hat die Steckdose zum Beispiel die Nummer 16, lässt diese sich schalten, in dem man dem Key on den Wert true oder false zuordnet. Also die Steckdose ein, oder ausschaltet. Die folgende Zeile dann einfach nach dem Unmounten der Festplatte ausführen und die Festplatte wird abgeschaltet.
curl -X PUT https://<bridge ip address>/api/<username>/lights/16/state -H "Content-Type: application/json" -d '{"on":false}' --insecureLinks
Get Started with Hue-Rest
Philips Hue: Timer für Lampen einstellen
Cloudflare Tunnel ist ein Service von Cloudflare, der eine verschlüsselte Verbindung zwischen der heimischen Server-Anwendung und dem Cloudflare-Netzwerk herstellt. Damit lässt sich eine lokale Webanwendung oder Website sicher und zuverlässig ins Internet bringen, ohne das dafür eine Port-Weiterleitung im Router eingerichtet werden muss. Ein von Cloudflare signiertes Zertifikat und damit eine sichere HTTPS-Anbindung gibt es gleich noch oben drauf.
Der Tunnel besteht aus zwei Komponenten: dem Client und dem Server. Der Client ist eine Software, die auf dem lokalen Server installiert wird und den Tunnel aufbaut. Der Server ist ein Teil des Cloudflare-Netzwerks, der den verschlüsselten Datenverkehr empfängt und über den Client an die Webanwendung oder Website weiterleitet.
Um den Cloudflare-Tunnel nutzen zu können, muss zunächst der Cloudflare-Deamon auf dem lokalen Server installiert und konfiguriert werden. Diesen gibt es als Docker-Container oder für Linux, Windows und Mac zum installieren. Anschließend muss die Webanwendung oder Website über das Cloudflare-Interface registriert und konfiguriert werden. Dabei werden verschiedene Einstellungen wie DNS-Records, SSL-Zertifikate und Sicherheitsregeln vorgenommen.
Sobald der Tunnel eingerichtet ist, wird der Datenverkehr von der lokalen Webanwendung oder Website sicher und zuverlässig über das Internet zum Cloudflare-Server geleitet. Dabei wird die Anwendung oder Website automatisch von der Cloudflare-Infrastruktur vor DDoS-Angriffen und anderen Bedrohungen geschützt.